Deep Q Learning w/ Tensorflow

Published on July 4, 2024 at 12:59 PM
Hey, what's up! It's been nearly a month since I've posted, so today I'm diving into an exciting subset of machine learning called reinforcement learning. In particular, I'll be implementing a Deep Q Network, which has been documented to achieve superhuman performance in complex tasks like Atari video games.
In my previous post, I explained how to train a neural network from from the ground up. I explained the math that goes into assembling a neural network, feeding data through it, and then propagating gradients backwards to update its parameters. While creating the network from scratch was interesting, in practice, it's often time consuming and error prone. Additionally, when scaling to the deep networks used in the modern world, keep track of every gradient becomes intractable. Most ML researchers in the industry today use libraries such as Tensorflow or Pytorch to build and train models efficiently. The biggest advantage of these libraries is the use of automatic differentiation. Instead of having to compute gradients by hand, Tensorflow and Pytorch automatically calculate gradients as you chain operations, allowing you to perform backpropagation in essentially one line of code.
Reinforcement Learning
Today, I'll be using Tensorflow to build a Deep Q Network, which was once a state-of-the-art algorithm in the field of reinforcement learning. Reinforcement learning is a learning process used to teach an agent how to act optimally in its environment [1]. The agent does this by maximizing a reward signal that encourages "good" actions and discourages "bad" ones. The basic paradigm is this: Every timestep, an agent observes a state and performs an action in response. Then, depending on what action, the environment returns a reward that scales with how favorable the agent is behaving. In a game of Snake, for example, the agent (the snake) would be rewarded for every apple it eats.
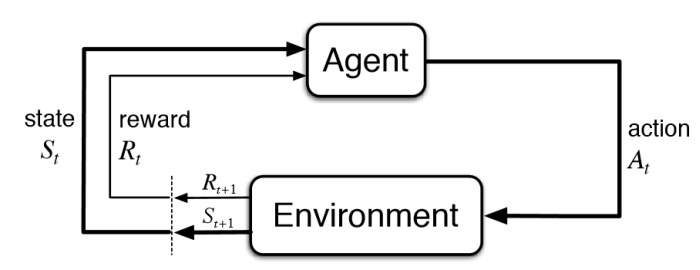

Q-Learning
Q-Learning is a particular algorithm in reinforcement learning that pairs every possible state and action in an environment into a pair (s, a), and gives each pair an assigned "Q-value." If our Q-value is perfect, then finding the best action in a state amounts to finding the state-action pair with the highest Q-value.
How do we find the Q value of each state? I won't go into the details, but at a high level, the agent starts out exploring, making random actions in an attempt to understand its environment. Most of its actions will result in a poor reward, but occasionally, it will make a favorable action. In response to the increased reward signal, the agent will update the Q-value of the state-action pair. If the agent encounters the same state in the future, it will see this action as more favorable and exploit its previous experience to choose the maximizing action. This tradeoff between making random actions and making intelligent ones is a fundamental problem in RL called the Exploration-Exploitation problem [2]. On one hand, if the agent makes random actions forever, it will never improve. On the other hand, if it only ever makes actions it thinks its best, it will be limited by its current knowledge of the environment and will never explore other actions that may be more optimal.
Implementation
I start out by importing the necessary libraries.
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
import numpy as np
Tensorfow is used to construct and train the model. Matplotlib is used to generate graphs of training performance. Numpy is used for data processing
def create_model():
model = models.Sequential()
# flatten/dense layers
model.add( layers.Input(4) )
model.add( layers.Flatten() )
model.add( layers.Dense(256, activation='relu') )
model.add( layers.Dense(2) )
return model
Here, I construct a Sequential feed-forward model with an input layer of 4 neurons, a hidden layer of 256 neurons, and an output layer of 2 neurons.
import gymnasium as gym
from collections import deque
import random
# some constants
REPLAY_SIZE = 32_000
MINIBATCH_SIZE = 64
REPLAY_START_SIZE = 500
EPSILON_START = 1
EPSILON_FINAL = 0.1
EPSILON_ANNEAL_FRAMES = 100
UPDATE_FREQUENCY = 1 # update network every n actions
TARGET_UPDATE_FREQUENCY = 20 # update target every n timesteps
DISCOUNT = 0.99
# experience replay buffer
experience_replay = deque(maxlen=REPLAY_SIZE)
# atari environment
env = gym.make('CartPole-v1') # remove render_mode in training
# actor and target models
actor = create_model()
target = create_model()
target.set_weights(actor.get_weights())
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
# tracking stuff
returns = []
total_timesteps = 0
Here, I create my training parameters. EPSILON represents the probability the agent takes a random action instead of one decided by the model (exploration). I also use a library called 'gym' to create the CartPole environment, a famous problem in ML where the goal is the balance a pole on top of a moving cart.
def loss(minibatch, actor, target):
# Unpack the minibatch into individual components
observations_batch, action_batch, reward_batch, next_observations_batch, done_batch = zip(*minibatch)
# Convert to tensors
observations_batch = tf.convert_to_tensor(observations_batch, dtype=tf.float32)
action_batch = tf.convert_to_tensor(action_batch, dtype=tf.int32)
reward_batch = tf.convert_to_tensor(reward_batch, dtype=tf.float32)
next_observations_batch = tf.convert_to_tensor(next_observations_batch, dtype=tf.float32)
done_batch = tf.convert_to_tensor(done_batch, dtype=tf.float32)
# Compute target Q-values using the DQN target network
future_rewards = target(next_observations_batch)
next_action = tf.argmax(future_rewards, axis=1)
target_q = tf.reduce_sum(tf.one_hot(next_action, 2) * future_rewards, axis=1)
target_q = reward_batch + (1 - done_batch) * DISCOUNT * target_q
# Compute predicted Q-values using the DQN network
predicted_q = actor(observations_batch)
predicted_q = tf.reduce_sum(tf.one_hot(action_batch, 2) * predicted_q, axis=1)
# Compute loss using the standard mean squared error (MSE) loss function
loss = tf.keras.losses.MSE(target_q, predicted_q)
return loss
This is the loss function for updating the network's parameters. The loss can found in the original paper [3], but I also had some help from [4] for implementing it in Tensorflow.
for episode in range(200):
print("EPISODE {}".format(episode + 1))
# reset env and setup variables
obs, info = env.reset()
previous_obs = None
# for now, a random action
action = env.action_space.sample() # to implement - use `env.action_space.sample()` for a random policy
# variable to keep track of episode status
episode_over = False
# count frames passed and collect data
total_reward = 0
frames = 0
states = []
if len(experience_replay) < REPLAY_START_SIZE:
print("Current size of buffer: {}".format(len(experience_replay)))
while not episode_over:
# sample observation/reward and process observation
previous_obs = obs
obs, reward, terminated, truncated, info = env.step(action)
total_reward += reward
# signal indicated episode has ended
episode_over = terminated or truncated
frames += 1
total_timesteps += 1
# only update observations/rewards every 2 states
states.append(obs)
# update data
if len(states) == 2:
experience_replay.append((states[0], action, reward, states[1], episode_over)) # s, a, r, s'
states.pop(0)
# sample new action
epsilon = EPSILON_START - (EPSILON_START - EPSILON_FINAL) * min(1, total_timesteps / EPSILON_ANNEAL_FRAMES)
if random.random() <= epsilon:
action = env.action_space.sample()
else:
action = actor(tf.expand_dims(obs, 0))
action = tf.math.argmax(action[0]).numpy()
# if we've reached UPDATE_FREQUENCY actions, update network (only if replay buffer is big enough)
if total_timesteps % UPDATE_FREQUENCY == 0 and len(experience_replay) >= REPLAY_START_SIZE:
# make network update
# get random sample from replay
minibatch = random.sample(experience_replay, MINIBATCH_SIZE)
# train
with tf.GradientTape() as tape:
loss_value = loss(minibatch, actor, target)
grads = tape.gradient(loss_value, actor.trainable_weights)
optimizer.apply_gradients(zip(grads, actor.trainable_weights))
# if we've reached TARGET_UPDATE_FREQUENCY frames, update target network
if total_timesteps % TARGET_UPDATE_FREQUENCY == 0:
# make target update
target.set_weights(actor.get_weights())
returns.append(total_reward)
print("TOTAL REWARD: {}".format(total_reward))
print("EPSILON: {}".format(epsilon))
print()
This is the code for running the CartPole simulation and training the agent. Every attempt is called an "episode", and experience is collected in a buffer called "experience_replay." Data is sampled from this buffer each timestep and used to train the agent. Below is a graph showing the total reward vs. timesteps:
The full code can be found in this Google Colab link: https://colab.research.google.com/drive/1C7Oam3wzREsbRYVPRCWIWOcuS2Vyl2Iu?usp=sharing
Until next time! 🚀
Sources: